Since we announced our collaboration with the World Bank and more partners to create the Open Traffic platform, we’ve been busy. We’ve shared two technical previews of the OSMLR linear referencing system. Now we’re ready to share more about how we’re using Mapzen Map Matching to “snap” GPS-derived locations to OSMLR segments, and how we’re using a data-driven approach to evaluate and improve the algorithms.
Mapzen has been testing and matching GPS measurements from some of Open Traffic’s partners since development began, but one burning question remained: were our matches any good? Map-matching real-time GPS traces is one thing, but without on-the-ground knowledge about where the traces actually came from, it was impossible to to determine how close to — or far from — the truth our predictions were.
Our in-house solution was to use the Mapzen Turn-by-Turn routing API to simulate fake GPS data, send the synthetic data through the Mapzen Map Matching service, and compare the results to the original routes used to simulate the fake traces. We have documented this process below.
You can also view this document in a Python notebook! The Python notebook comes with Docker containers that run local instances of Valhalla, the open-source code that powers both Mapzen Turn-by-Turn and Mapzen Map Matching.
Route Generation
The first step in route generation is picking a test region, which for us was San Francisco. Routes are defined as a set of start and stop coordinates, which we obtain by randomly sampling venues from Mapzen’s Who’s on First gazetteer for the specified city. Additionally, we want to limit our route distances to be between ½ km and 1 km because this is the localized scale at which map matching actually takes place.
For each route, we then pass the start and end coordinates to the Turn-By-Turn API to obtain the coordinates of the road segments along the route.
Simulating GPS data
Now that we have a set of “ground-truthed” routes, meaning route coordinates and their associated road segments, we want to simulate what the GPS data recorded along these routes might look like. This involves two main steps:
- resampling the coordinates to reflect real-world GPS sample frequencies
- perturbing the coordinates to simulate the effect of GPS “noise”
To resample the coordinates, we use the known speeds along each road segment to retain points along the route after every nn seconds.
To simulate GPS noise, we randomly sample from a normal distribution with standard deviation equal to a specified level of noise (in meters). We then apply this vector of noise to a given coordinate pair, and use a rolling average to smooth out the change in noise between subsequent “measurements”, recreating the phenomenon of GPS “drift”.
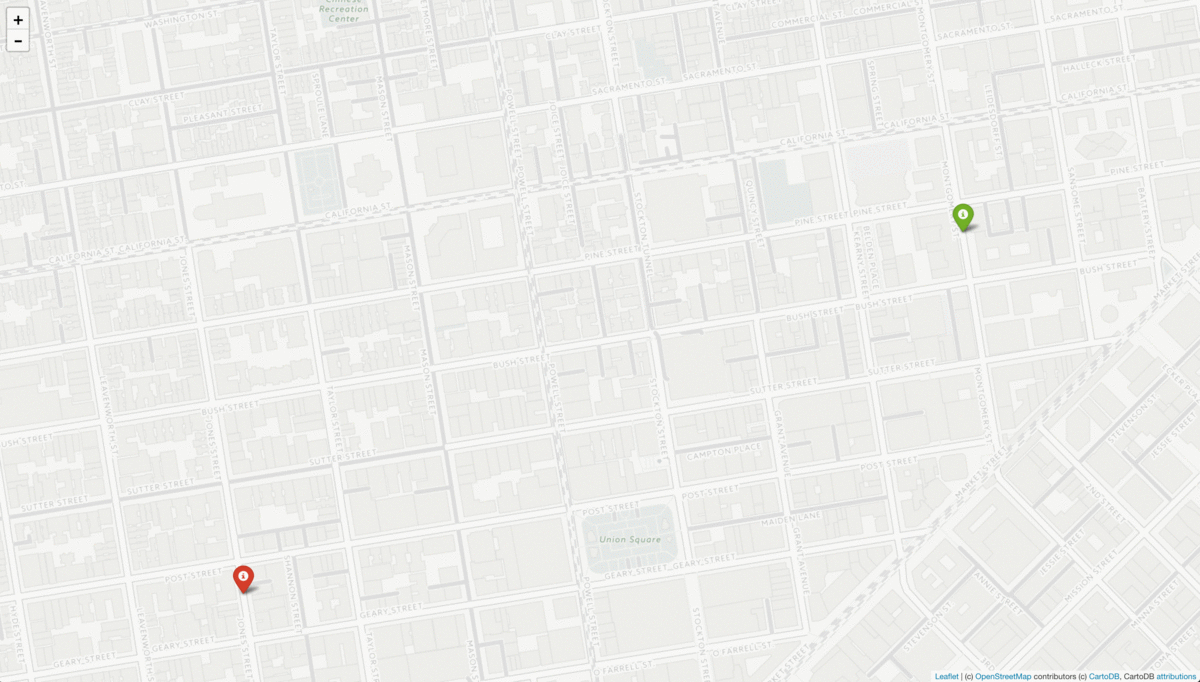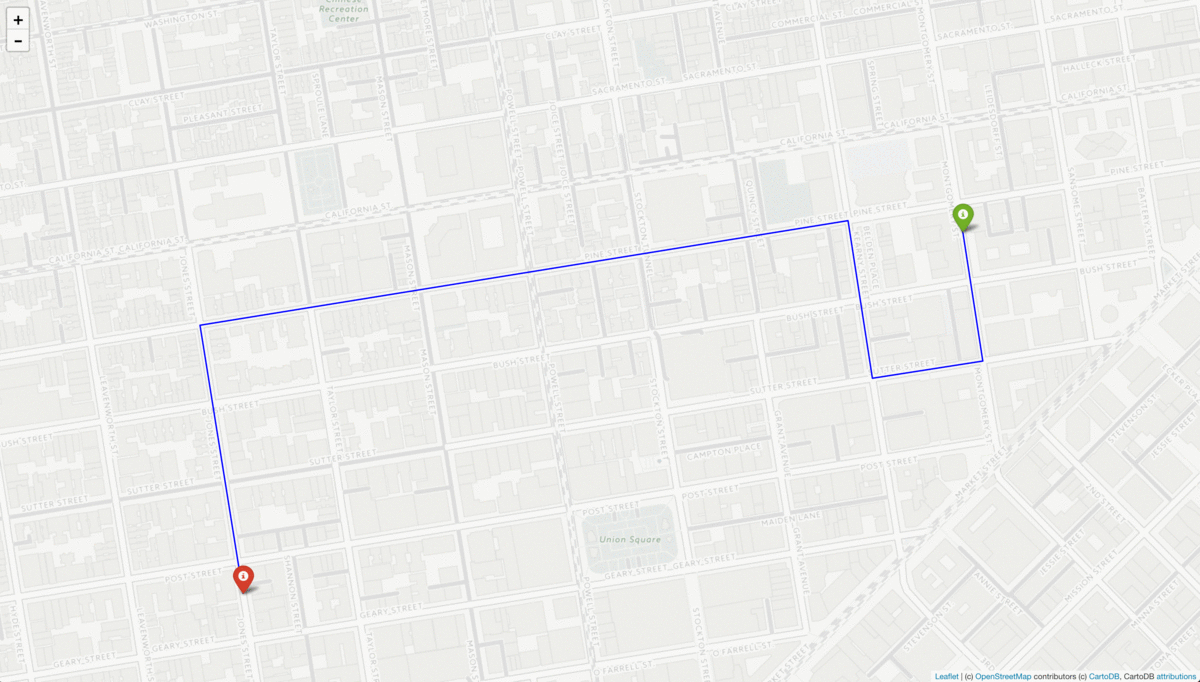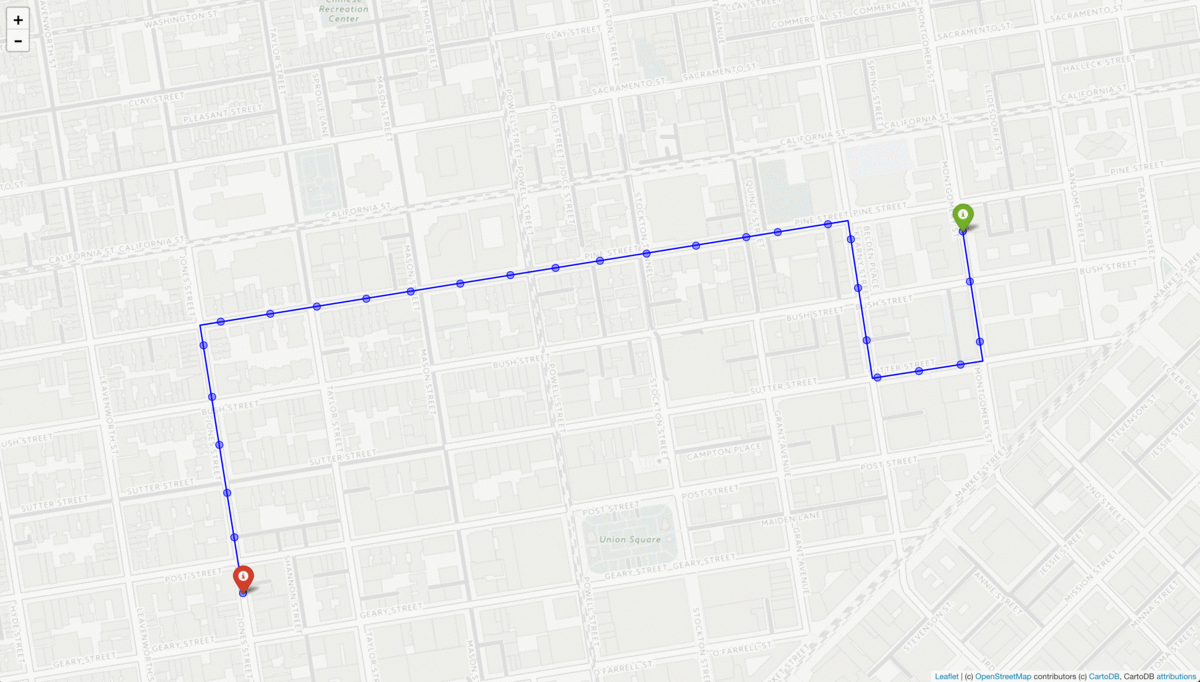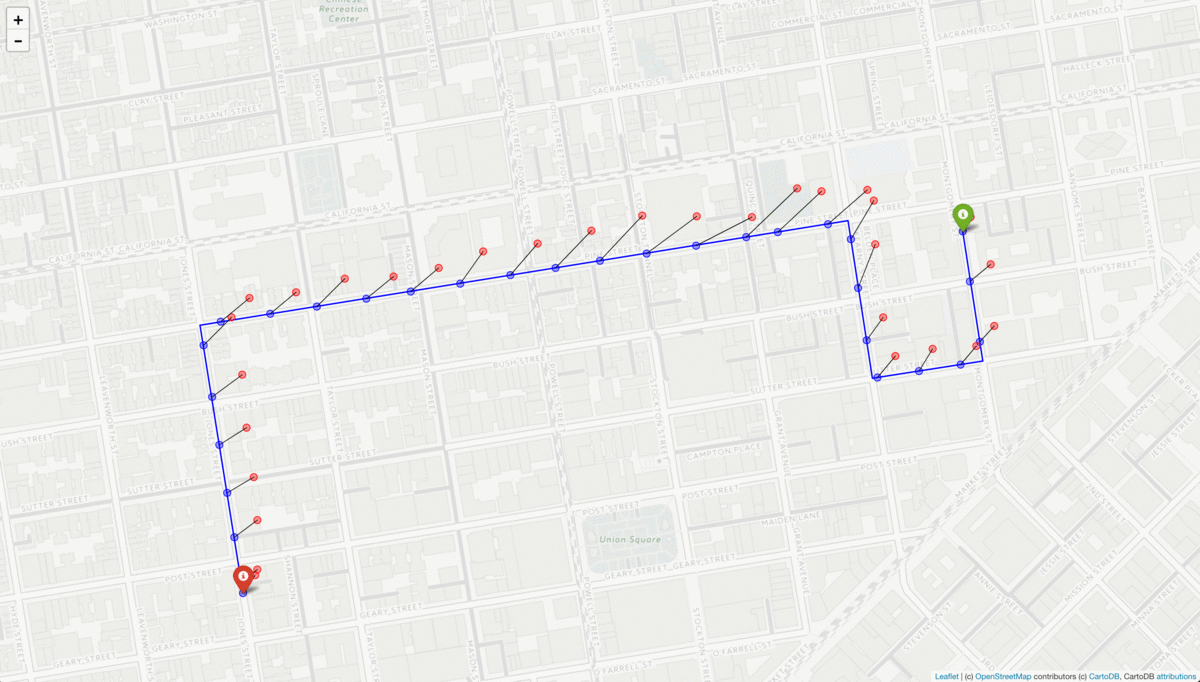
A route is generated from random start and end coordinates and resampled at 5 second intervals (blue dots). The resampled points are then perturbed with noise sampled from a gaussian distribution with mean 0 and standard deviation of 60. The resulting “measurements” (red dots) represent a simulated GPS trace.
Since we are interested in assessing the performance of map-matching under a variety of different conditions, we define a range of realistic sample rates and noise levels:
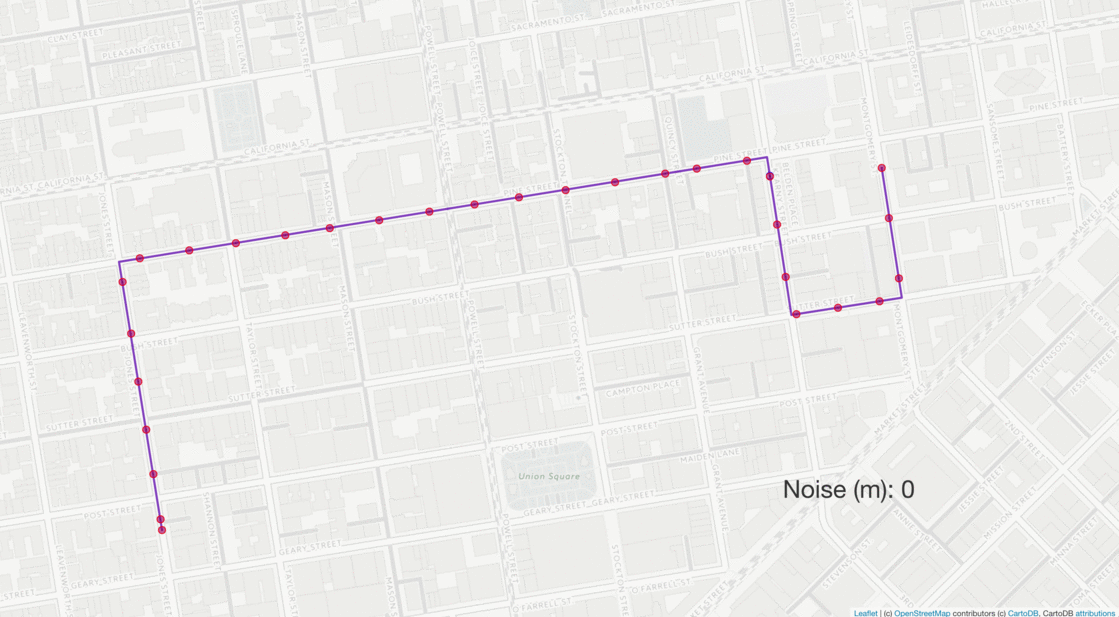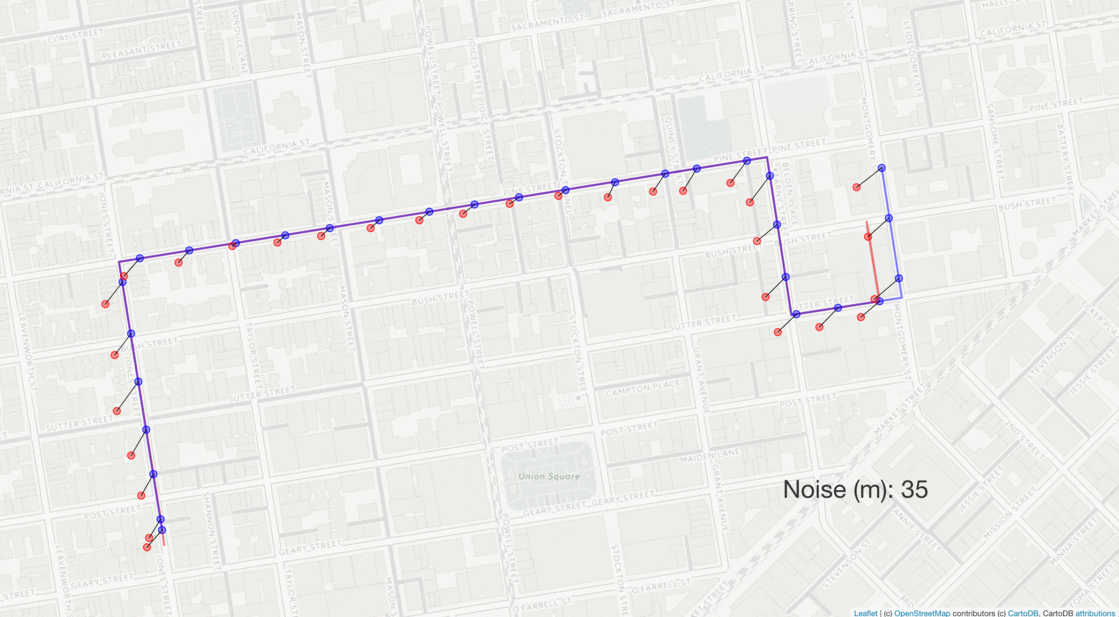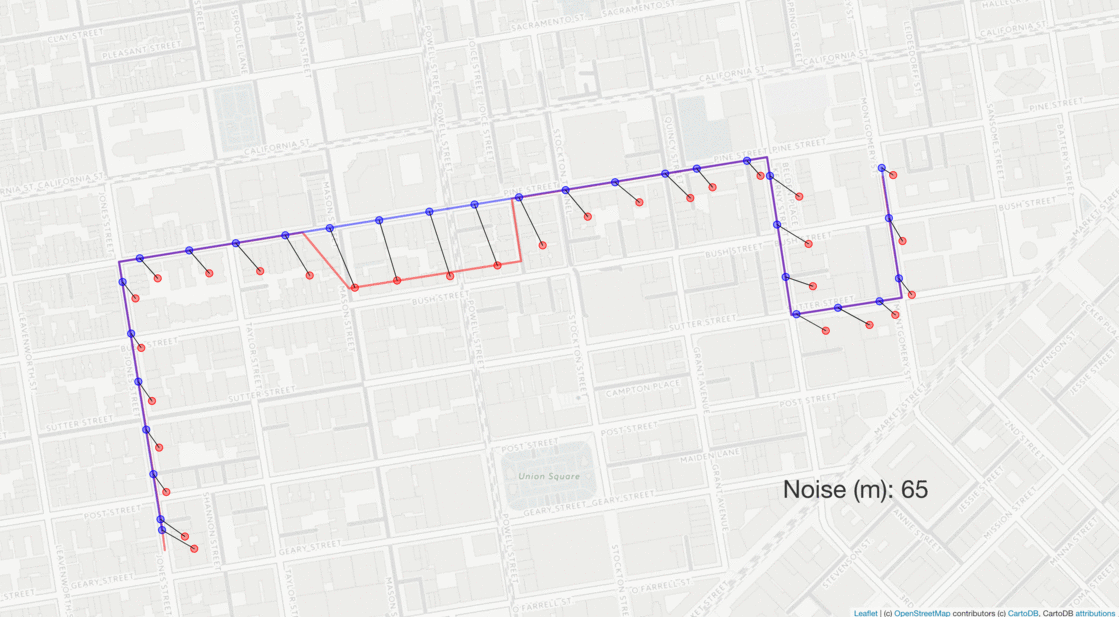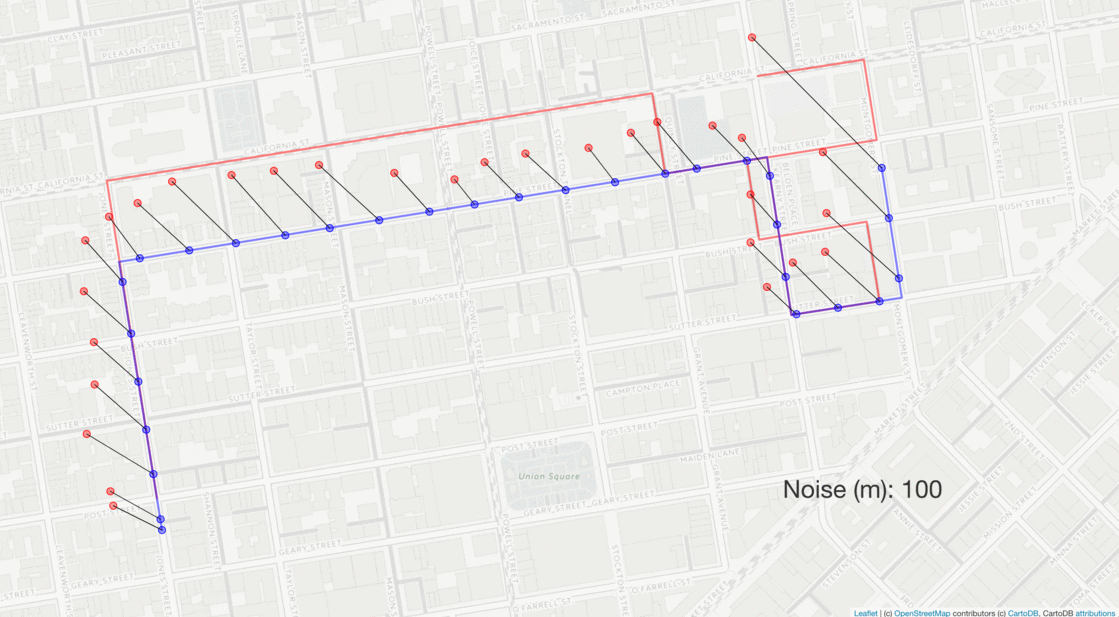
The same route is perturbed with varying levels of gaussian noise (red dots) with standard deviations ranging from 0 to 100 m. The resulting matched routes are shown as red lines, which only deviate from the true route at higher levels of noise.
Iterating through each our 200 routes at 5 sample rates and 21 levels of noise, we simulate 21,000 distinct GPS traces. We then pass each of these simulated traces through to the map-matching service, and compare the resulting routes against the ground-truthed, pre-perturbation route segments.
Scoring & Validation
In order to validate our matched routes, we need an effective method of scoring. Should Type I error (false positives) carry as much weight as Type II (false negatives)? Should a longer mismatched segment carry a greater penalty than one that is shorter?
We adopt the scoring mechanism proposed by Newson and Krumm (2009), upon whose map-matching algorithm the Valhalla Meili map-matching service is based:
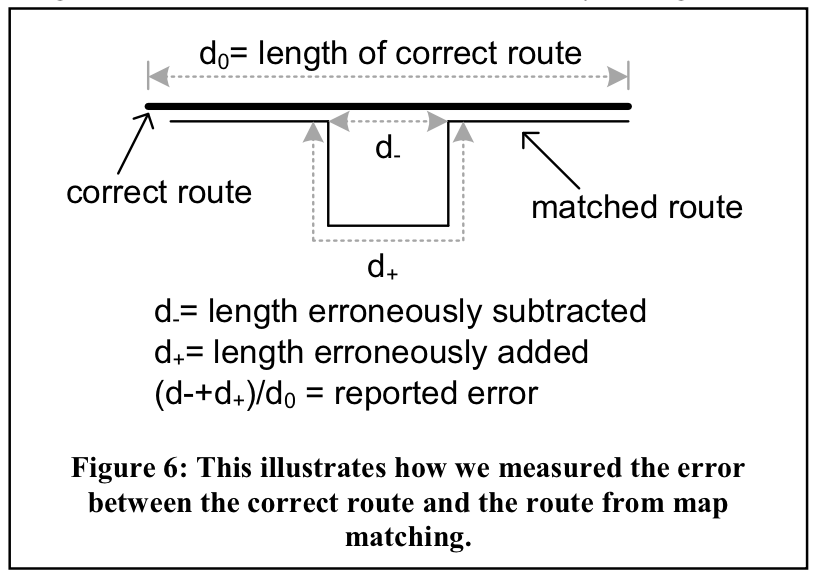
From Newson and Krumm (2009)
In the above schematic, d₊ refers to a false positive or Type I error, while d₋ represents a false negative, or Type II error. The final reported error is a combination of both types of mismatches, weighted by their respective lengths.
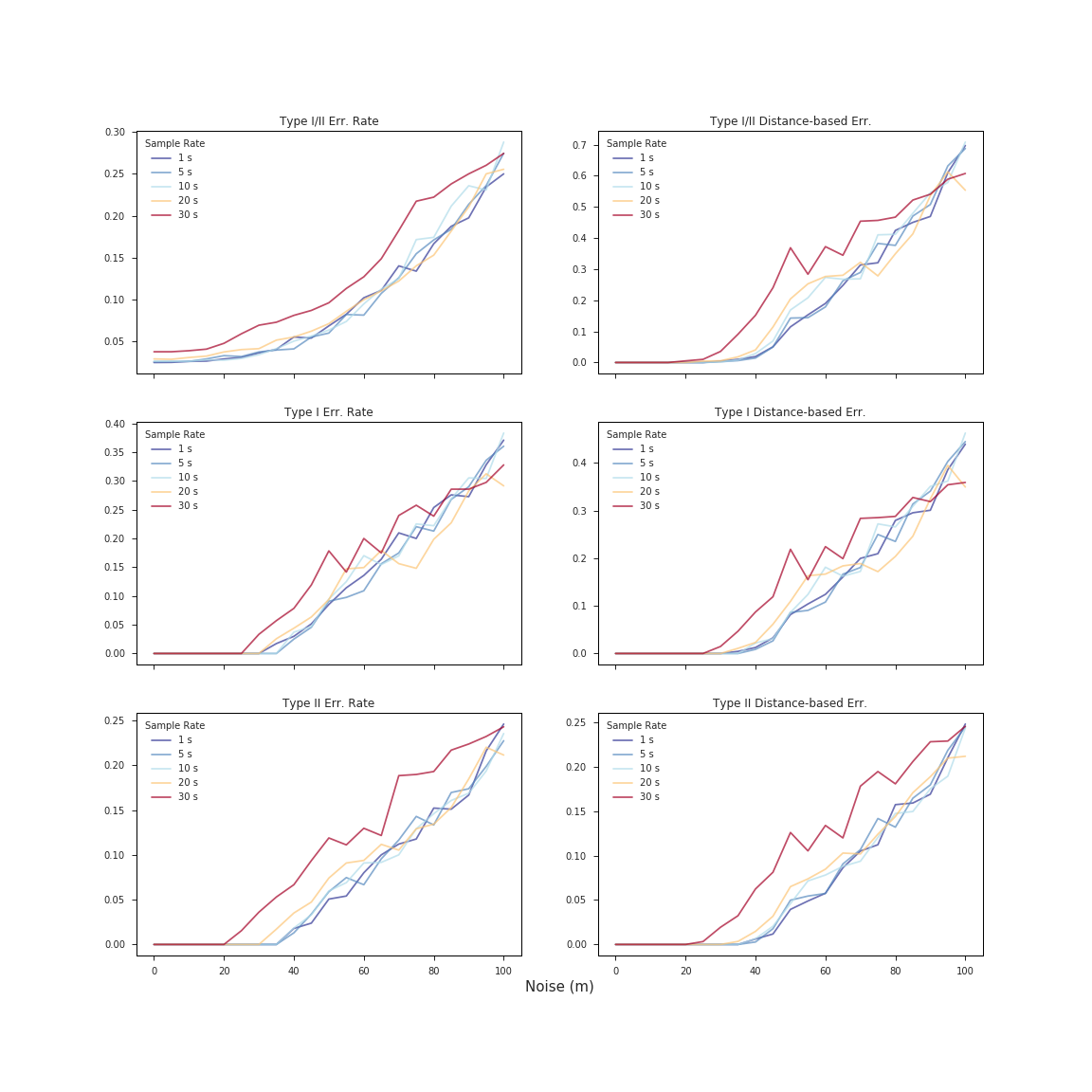
The graphs below represent the median scores for 6 error metrics applied to each of our 21,000 routes, broken down by sample rate and noise level. Plots in the left column are based solely on error rate, i.e the percentage of Type I, Type II, or Type I/II mismatches. The right-hand column shows the same metrics as the left, but weighted by segment length. The top right plot thus represents the metric used by Newson and Krumm, and the two plots below it represent the same value broken out by error type.
Results
There is a lot of valuable information to be gleaned from our validation process. The main takeaways are summarized below:
- Below 50 m of noise, we obtain a median match accuracy of 90% or better.
- Clearly the positional accuracy of GPS data (vis-a-vis noise level) has a huge impact on rate of mismatch. However, there is little to no impact on error rates at noise levels below 20 m.
- Sample rate also has a significant effect on performance. What that effect is, however, depends significantly on the positional accuracy of the data. Higher frequency sample rates clearly perform better at lower levels of noise, but there exists a very consistent point of inflection (~80-90 m) about which the performance of low sample rate GPS traces (red) improves relative to that of the higher sample rates (blue). These results, consistent with the findings of Newson and Krumm (2009), suggest that lower sample rates tend to be more robust against mismatch error at higher levels of noise.
- There does not appear to be a significant difference in the trends between the distance-based error metrics and those that do not consider segment length.
- Similarly, the Type I, Type II, and Type I/II error rates very closely track one another, although the pattern of inflection described in (3) appears more pronounced in the Type II-based metrics.
Ultimately, our validation allows us to state with a greater measure of confidence that our map-matching is working as intended, at least in San Francisco:
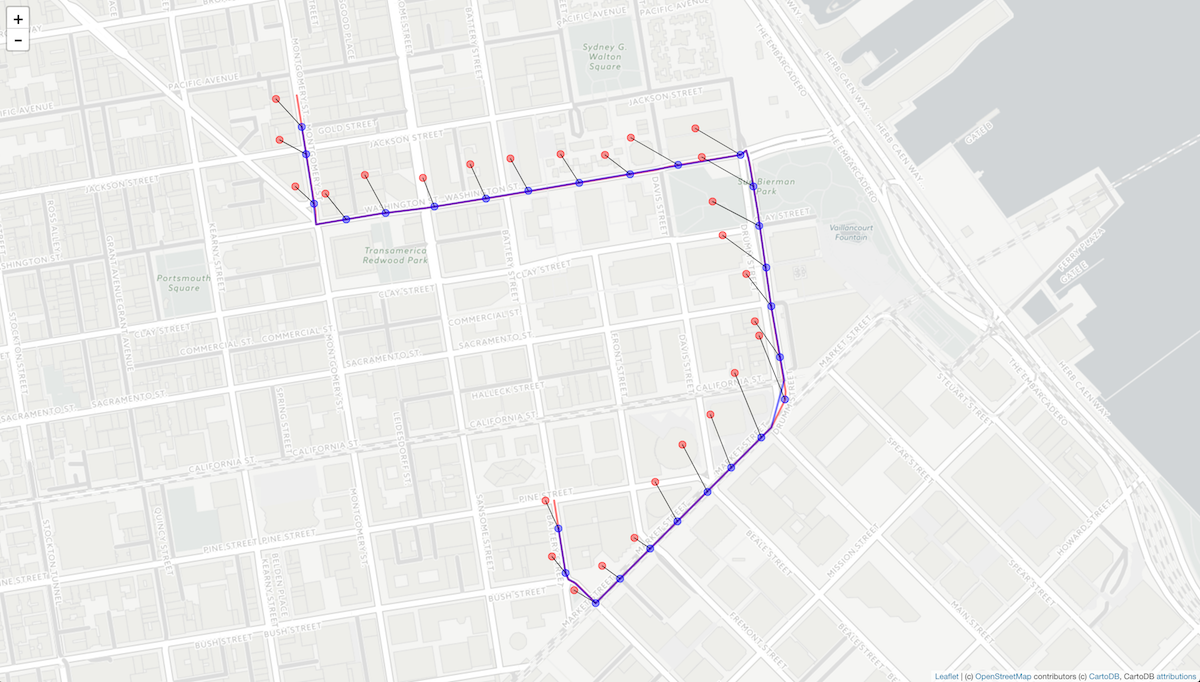
A perfect match on a route with 80 m of noise (5 s sample rate)
In the next installment of this series, we will see how we can actually use these error metrics to optimize the performance of our map-matching algorithm based on the quality of the data made available to us.

{kind=link}