The Terrain Tiles dataset consists of thousands of digital elevation model (DEM) data sources at various resolutions from around the globe, merged together, split into billions of map “tiles”, and stored on AWS’s S3 storage system. We developed a highly scalable system on top of AWS Lambda, Batch, and S3 in order to convert the sources, composite/merge them together, and split the merged files into tiles as quickly as possible.
Simplifying dependencies with containers
Building the Terrain Tiles dataset requires very recent versions of the popular geospatial software library GDAL. Since it’s relatively difficult to get the required version of GDAL installed, we built Dockerfiles to help us build with a consistent combination of operating system and dependencies. The Dockerfiles we created include the correct versions of GDAL and the Python software that controls it to perform the various tasks required to build the tiles.
Generating cloud-optimized GeoTIFFs
The raw data comes from a wide range of sources from all around the world in different formats. The first step in the Terrain Tiles process is to convert these images into Cloud Optimized GeoTIFFs and store them on S3 so our compositing toolchain can interact with them efficiently. Cloud-optimized GeoTIFFs store lower-resolution overviews in predictable locations within the same file as the original GeoTIFF, allowing us to utilize GDAL’s built-in support for HTTP range requests.
To perform the transcoding step, we submit AWS Batch jobs that run the transcode script across the provider’s data. The transcoder script supports direct downloads from the provider, but in the case of a particularly complicated access methodology, we download the provider’s data to our S3 bucket first and transcode from there. The transcoder script runs GDAL commands and writes the output cloud-optimized GeoTIFFs to a different S3 bucket.
Finally, the transcode script looks for areas in the image that should be transparent and builds a polygonal footprint for the coverage of the data using rasterio. That polygon, along with metadata about the source image, goes into a data of footprints that will be used during the compositing process.
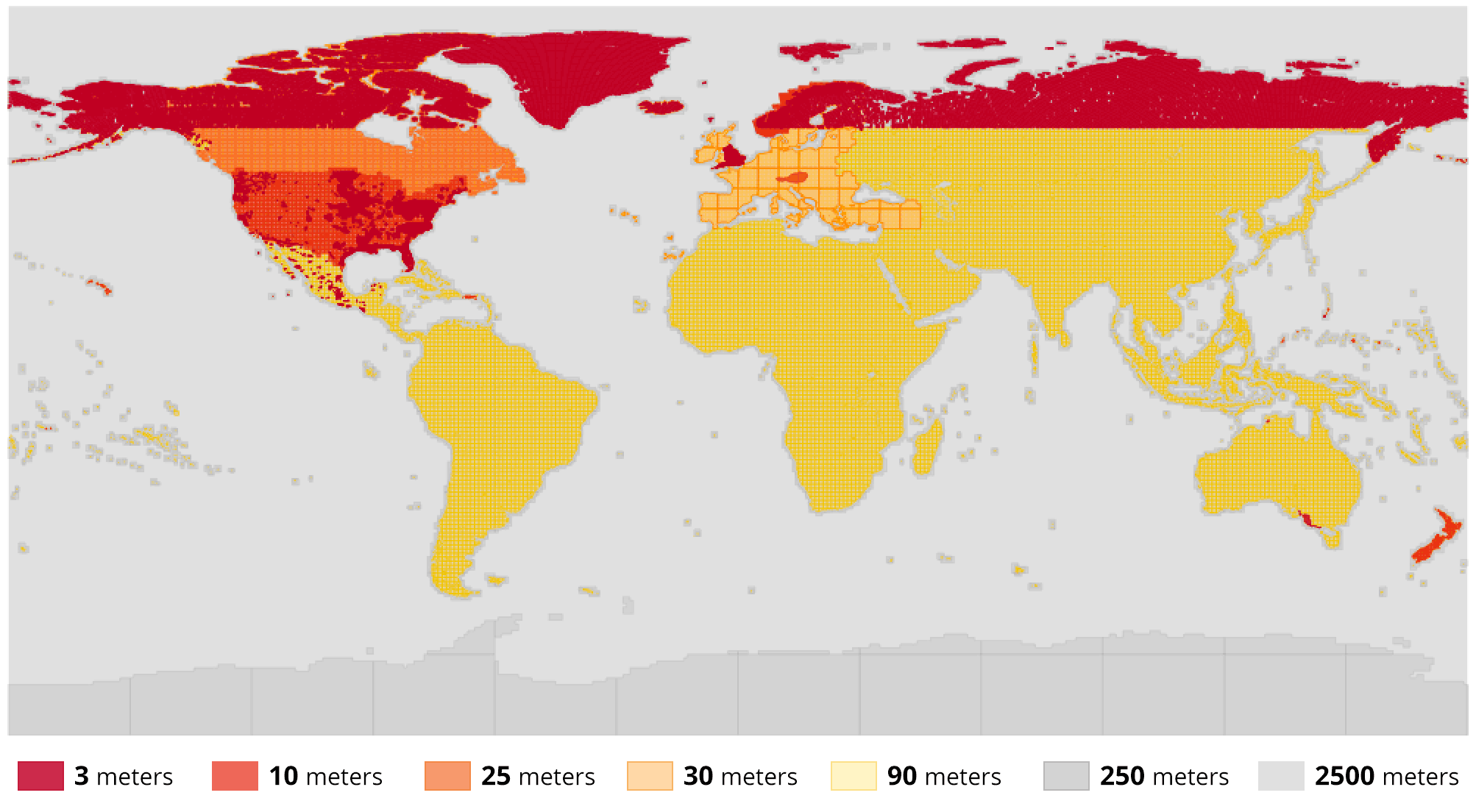 An overview rendering of the roughly 32,000 source footprints in the footprints database.
An overview rendering of the roughly 32,000 source footprints in the footprints database.
Generating composite tiles
Once the source data has been transcoded into the cloud-optimized GeoTIFF format and indexed into a database, we overlay those sources on top of each other to form the composite outputs that become the the Terrain Tiles output. Our compositing software, called Marblecutter, takes a bounding box, looks for source data in the footprints database, and fetches the pieces of the source data it needs to build the composite image.
Since we are compositing from cloud-optimized GeoTIFFs, the compositing software (which uses GDAL) only has to make HTTP range requests for the specific data it needs rather than downloading the entire source image. This dramatically speeds up the rendering process, especially when running in a cloud provider like AWS Batch.
We built two systems that use the marblecutter compositing library: one that runs in AWS Lambda to generate tiles on the fly in response to HTTP requests, and another that runs with AWS Batch to generate bulk tiles to cover the entire world.
The AWS Lambda tiler uses the AWS API Gateway system to respond to HTTP requests and re-generate a composite tile every time. This is particularly useful for debugging changes to the footprints database, allowing us to tweak the ordering or precedence of source images to ensure the output tiles use the best possible source data. (If you do see any data issues, please file an issue.)
Finally, the marblecutter library is used to recursively generate a “pyramid” of map tiles starting from a particular e.g. zoom 9 tile and rendering every tile all the way down to a maximum zoom of e.g. zoom 15. This pyramid renderer system is run in a multithreaded Python environment across hundreds of AWS Batch-controlled EC2 cloud instances. Each Batch job enqueues an internal job on the multithreading queue for each tile in the pyramid of tiles. Each tile is also rendered in three different formats, meaning that each zoom 9-15 Batch job we run renders more than 16,000 tiles.
As we scaled this process up, we ran into unforeseen bottlenecks. First, the footprints database quickly ran out of available connections and the geospatial queries overwhelmed the CPU. To solve that, we added a step at the beginning of the Batch process to make a local in-memory cache of the footprints relevant to the pyramid of tiles getting rendered. Second, issuing requests for Cloud-optimized GeoTIFFs directly to S3 was slowing down compositing so we added a CloudFront cache in front of S3 to speed up the composite process. Finally, the S3 API couldn’t handle the burst of high throughput PUT requests, so we worked with the S3 team to develop a method to support higher instantaneous throughput by prefixing our keys with an MD5 hash. Once we generated the tiles with an hash prefix, we copied the tiles into place without the MD5 hash.
Using this setup on AWS Batch, we are able to generate more than 3.75 million tiles per minute and render the entire world in less than a week! These pre-rendered tiles get stored in S3 and are ready to use by anyone through the AWS Public Dataset or through Mapzen’s Terrain Tiles API.


{kind=link}