In our recent interpolation blog post, Peter mentioned how address geocoding in Mapzen Search is powered by two important open-source projects: OpenStreetMap and OpenAddresses.
Mapzen is proud to help improve OpenAddresses data coverage and we’d like to celebrate two important milestones for the project. OpenAddresses surpassed 400 million address in January 2017, and we are on track to add the 2,000th source in March. That’s 8.2GB of open-data! 🎉
A short history of OpenAddresses
OpenAddresses launched in March 2014. Street addresses are sourced directly from the government agencies responsible for creating and maintaining cadastral information.
While OpenStreetMap has address coverage in more places, OpenAddresses covers six times the number of addresses overall and often has more complete coverage in those fewer places. (If you need to add a missing address, OpenStreetMap is the best place to contribute.)
Together these complimentary projects have nearly half a billion addresses!
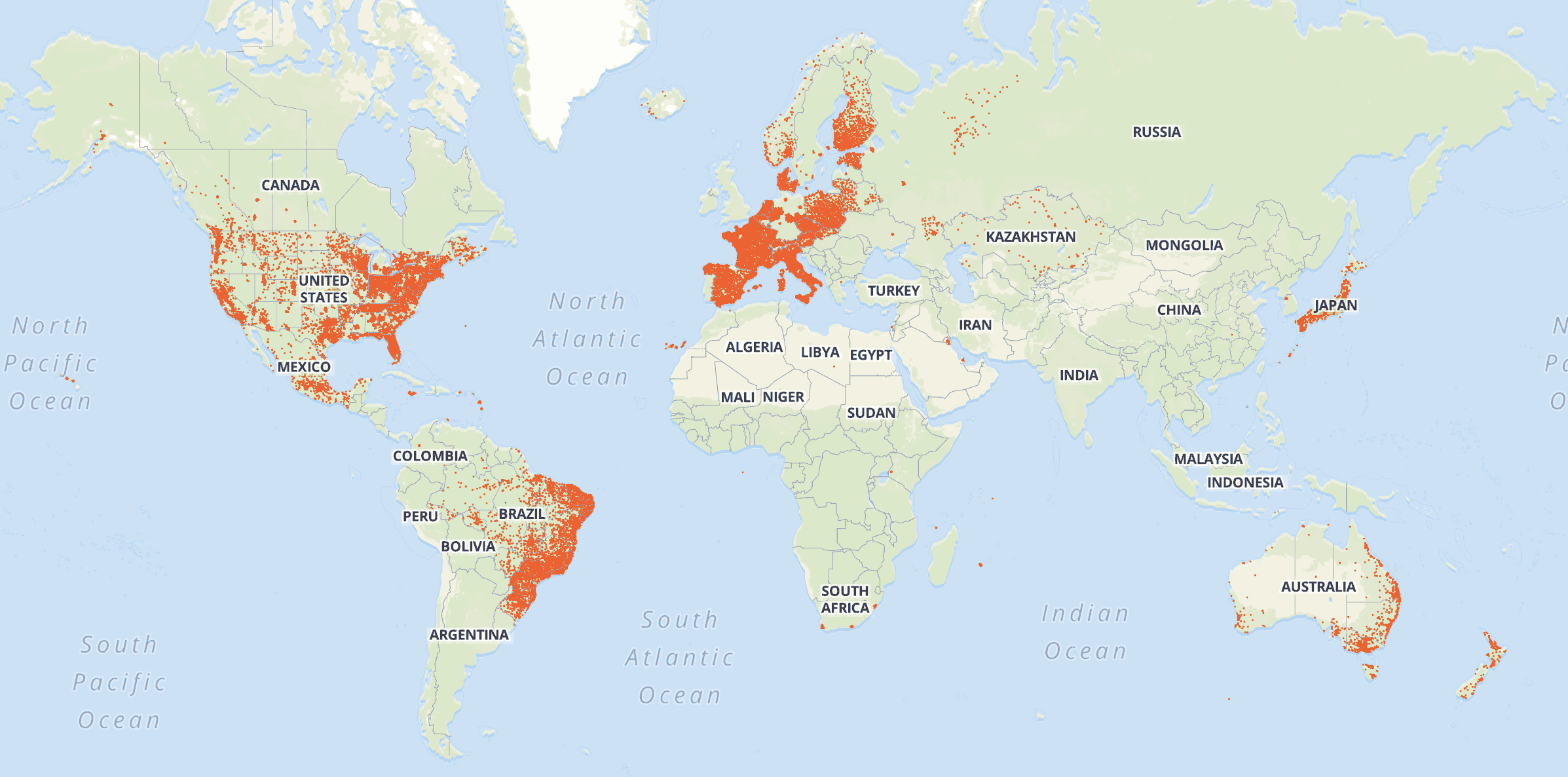
March 2017: 406 million addresses (up from 200 million in July 2015!)
Ian Dees co-founded OpenAddresses with Nick Ingalls, and Mike Migurski has been an important contributor. Major props also to our friends at Mapbox for help with the OpenAddresses project, and to Esri who enable easy access to address and parcel features in over 4,000 government open-data portals!
After a period of rapid expansion in 2015, the addition of new OpenAddresses sources started to taper off. Most of the “easy” sources were played out and keeping existing sources fresh became its own task. The project hit 200 million addresses with 1,000 sources in October of 2015.
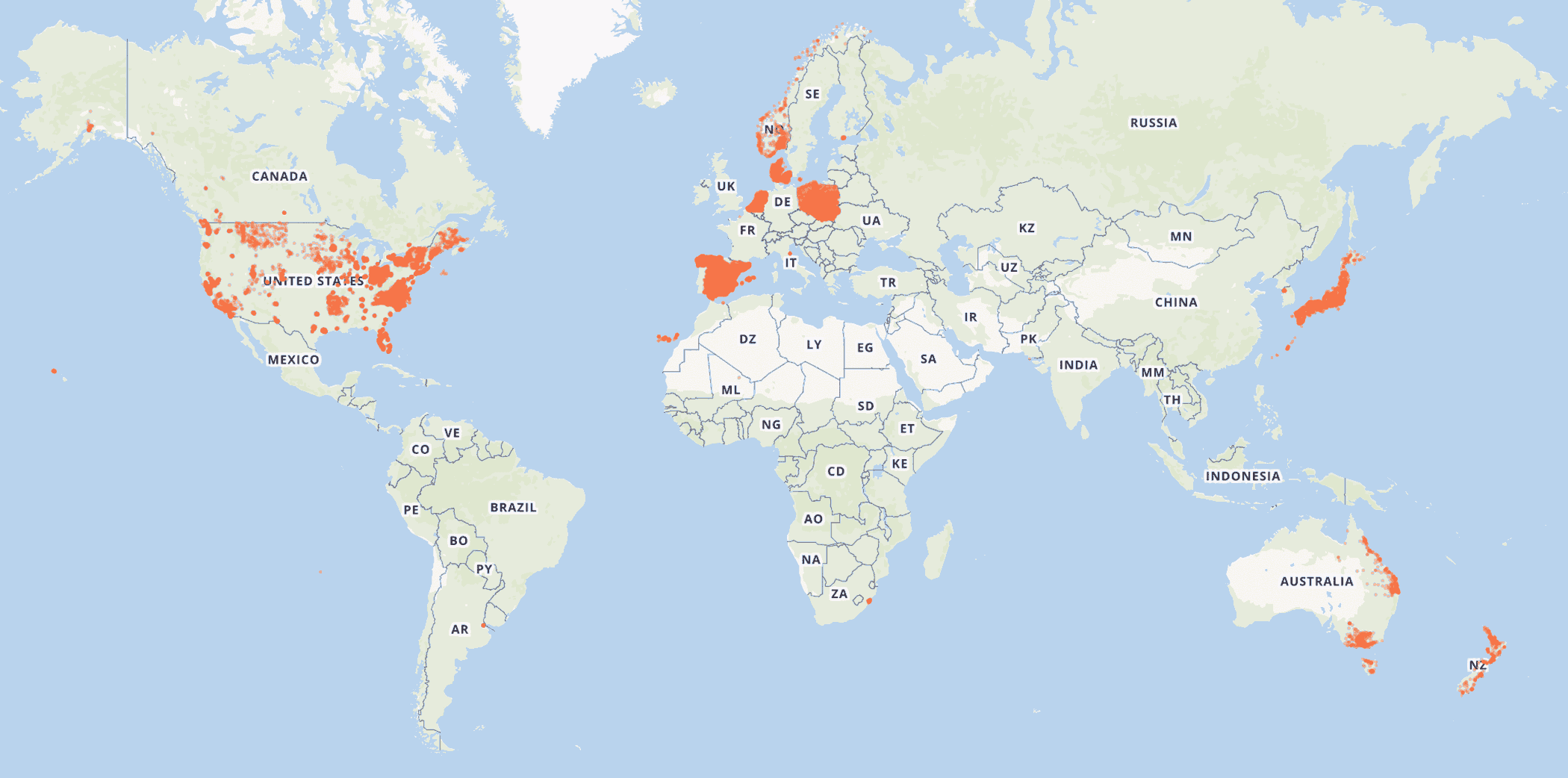
There were still some big new sources added to OpenAddresses in 2016, including national datasets in Australia, Italy, Mexico (where Mapbox is currently working on another huge update), Austria, parts of Germany, parts of Switzerland, Finland, Kazakstan, parts of Russia, and several major cities around the world. The United States saw some improvement in early and mid-2016, and the pace has picked up quite a bit the last 6 months.
Globally, the 300 million mark was reached in December 2016, and in January 2017 a contributor added nationwide coverage for Brazil, bumping worldwide coverage up to 400 million addresses.
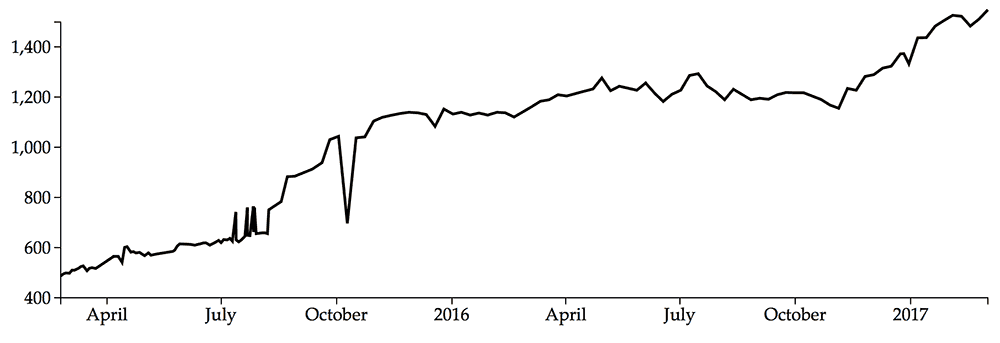
The number of successful sources per build is surging. There are currently 1965 total sources.
Mapzen + OpenAddresses
Stephen Hess with Mapzen Search started helping out with OpenAddresses in October of 2015 for Pelias, landing his first Pull Request in November 2015. Since then he’s added many new sources, gardening existing sources to standardize their configurations and refreshing them when they go stale. Improving documentation (including a section on using regex to magic data out of difficult sources) has also been a focus. Ian and Mike have helped with pull requests for sources and kept the OA machine humming.
In the fall of 2016 Nathaniel Vaughn Kelso inventoried coverage in the United States and started filing issues documenting remaining major gaps.
That work is organized in several Github projects 1, 2, and 3 around four priority tiers of (1) major cities and counties, (2) medium sized cities and counties, (3) regionally important cities and counties, and (4) small towns and rural counties. After that initial round of Github issues was filed, we received many tips via issue comments pointing to possible data sources —thank you!
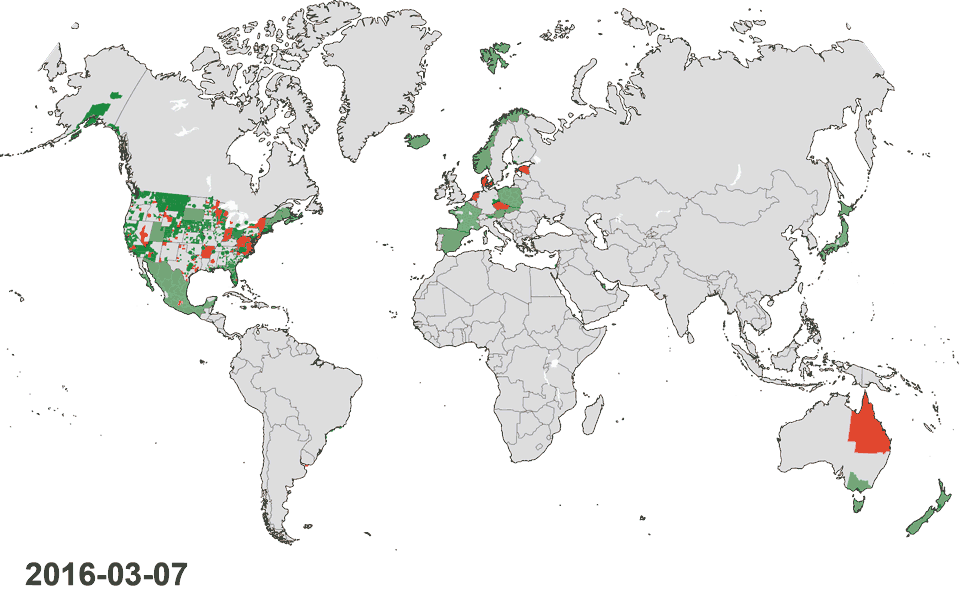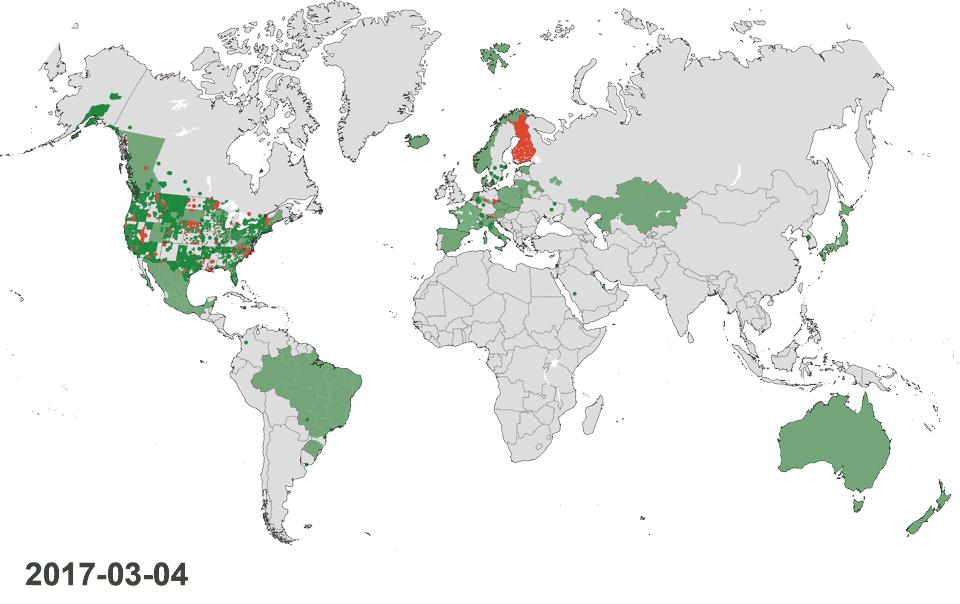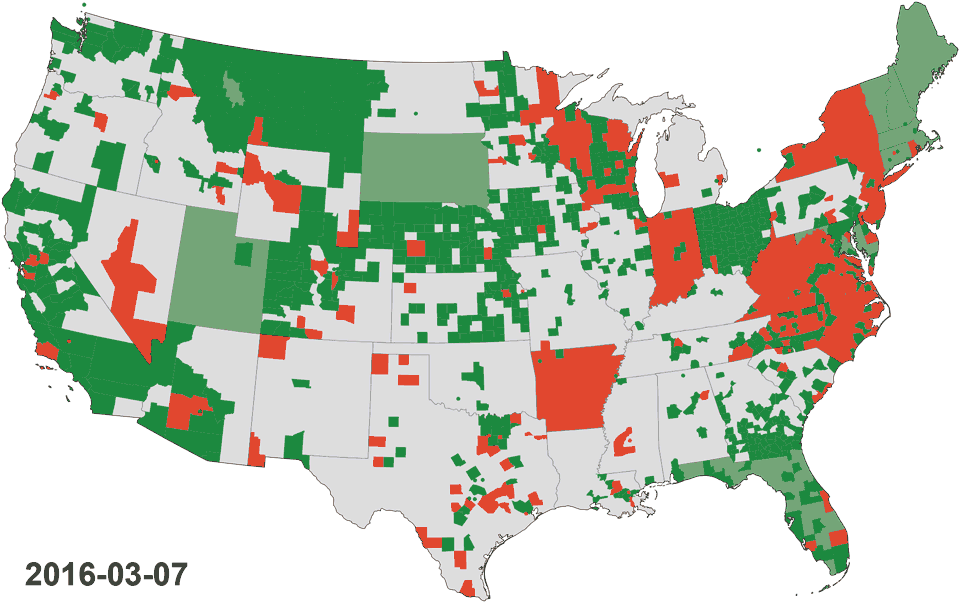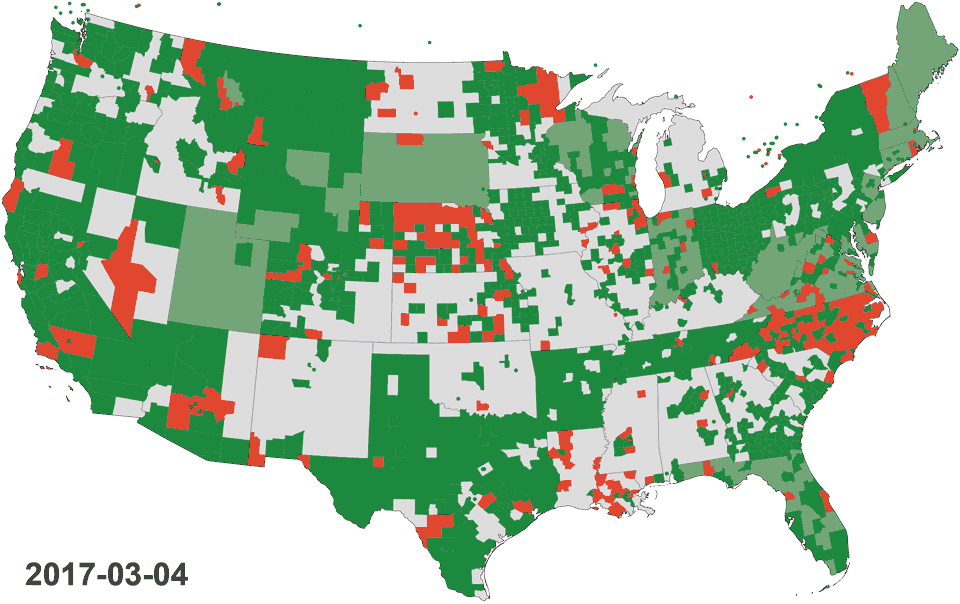
Animated map: Progress adding sources during the last 12 months globally and in the United States of America. Learn about the orange sections below.
Starting in September, 2016 we have been lucky to work with Justin Meyers as a data prospector to improve coverage in the United States. The pace picked up quite a bit in November once we got fully online, and we’ve found a few international sources along the way.
Workflow
Most missing sources take just 15-30 minutes to research on the web and add to OpenAddresses with a pull request via Github, where the project is managed.
Single data sources are often at the locality or county level with 10,000 to 200,000 addresses. But sometimes we get lucky and can add millions of addresses with an entire state (like in Texas), or a metro area (like Detroit) spanning multiple counties.
For a lot of the smaller counties in the United States we pick up the phone and dial the local planning department or tax accessor to find the data. In some cases we’ve found the sheriff’s office has addresses as part of a federally sponsored e911 project.
There are a few open-data holdouts (we’re looking at you, Philly suburbs) where the data is available, but under closed terms and requires a huge fee. Hopefully the Pennsylvania governor’s new open-data initiative will help.
Most data is available as a web service or download, but sometimes the data provider will ship us a DVD!

Purchasing data for Sierra County, California via snail mail. We had to buy a DVD reader. 📀
Contributing
In the last 12 months a lot of data has been added, jumping roughly from ~240 million in February 2016, to ~275 million in September 2016, and to 406 million addresses today. The best part is over 100 million addresses have come from people besides us, including: davidchiles, astoff, sergiyprotsiv, and thatdatabaseguy. Thank you! 😃️️
OpenAddresses would love your help. The contributing guidelines is a good place to start.
Curious about data gaps? Use OpenAddresses’s dot map to browse data coverage. If you see a gap look thru the issues to see if someone is already working on it. When you find a data source for the missing place, add your research to an existing issue or create a new issue.
Are you more technically inclined? Create a JSON config file for new sources for issues marked ready for PR, or look through sources which have gone stale (listed as “Lost sources” and colored orangeish-red in the animated maps above) and give them some love by adding a missing conform.
And if you are available to user test some new features we are building please say hello@mapzen.com.
Happy mapping!





{kind=link}
{kind=link}