The short version

All the places! Still not a magic pony!! Yet!!!
The longer version
Mapzen is building a gazetteer of places. Not quite all the places in the world but a whole lot of them and, we hope, the kinds of places that we mostly share in common. A gazetteer is a big list of places, each with a stable identifier and some number of descriptive properties about that location. An interesting way to think about a gazetteer is to consider it as the space where debate about a place is managed but not decided. We call our gazetteer “Who’s On First” (or sometimes “WOF” for short).
According to Wikipedia, Who’s on First:
…is a comedy routine made famous by Abbott and Costello. The premise of the sketch is that Abbott is identifying the players on a baseball team for Costello, but their names and nicknames can be interpreted as non-responsive answers to Costello’s questions. For example, the first baseman is named “Who”; thus, the utterance “Who’s on first” is ambiguous between the question (“Which person is the first baseman?”) and the answer (“The name of the first baseman is ‘Who’”). “Who’s on First?” is descended from turn-of-the-century burlesque sketches that used plays on words and names. Examples are “The Baker Scene” (the shop is located on Watt Street) and “Who Dyed” (the owner is named Who). In the 1930 movie Cracked Nuts, comedians Bert Wheeler and Robert Woolsey examine a map of a mythical kingdom with dialogue like this: “What is next to Which.” “What is the name of the town next to Which?” “Yes.” In English music halls (Britain’s equivalent of vaudeville theatres), comedian Will Hay performed a routine in the early 1930s (and possibly earlier) as a schoolmaster interviewing a schoolboy named Howe who came from Ware but now lives in Wye.
Which sort of sums up the “problem” of geo, nicely. It might be easier, perhaps, if we all understood and experienced the world as coordinate data but we don’t, so the burden of “place” and its many meanings is one we trundle along with to this day.
Our gazetteer is absolutely not finished – both in terms of data coverage as well as data quality – so, in the near-term, you should adjust your expectations accordingly when you approach the data.
We are releasing the data now because we believe it is important not just to articulate our goals and intentions around the project but also to back them up with tangible proofs. Think of this blog post, and the data we are publishing today, as the arc and direction of our efforts but not necessarily where they will land.
Ours is not the first gazetteer (and hopefully not the last). Many gazetteers have existed before. Notable examples include:
- The Getty Institute’s Thesaurus of Geographic Names
- The Alexandria Digital Library
- Yahoo’s GeoPlanet
- Geonames
- The joint effort of the New York Public Library (NYPL) and the Library of Congress (LoC) to create an historical gazetteer
- The NYPL’s recently announced Space/Time Directory
- NaturalEarth
- Quattroshapes
We use Quattroshapes as the foundation for our data set, as it has most of the stuff, in most of the places, most of the time.
From there we are merging in relevant additions (geometries and metadata alike, as the various licenses permit) from Natural Earth, GeoPlanet, GeoNames and the Zetashapes project.
People who’ve been around this problem for as long as we have may be thinking: Doesn’t this mean that the coverage for certain place types (many neighbourhoods around the world and in some countries even localities) will be lacking to start with? The answer is: Yes. One of our immediate goals is to identify which places in the GeoPlanet dataset lack both a concordance with and a corresponding record to Quattroshapes. Once we have that list we can import the names and hierarchies for those places from GeoPlanet at which point the coverage should improve immediately. Many of those places will lack coordinate data at the time of import but we believe that is a problem that can be tackled in time.
Ours is not the first effort to create an open and comprehensive data set of the world. We think that each one of the projects mentioned above offers their own unique contributions and we hope that by “smushing” them all together we can start to create something greater than the sum of its parts.
Also, all the data is made available under a Creative Commons Zero designation.
We make use of a number of open data sources, some of whom do require attribution. We have listed them over here.
The long version

Long version is long. You might want to get a cup of coffee or maybe a drink if you’ve been thinking about this sort of thing for as long as we have (or maybe longer).
What is a “gazetteer” anyway?
Like we said before, a gazetteer is a big list of places, each with a stable identifier and some number of descriptive properties about that location. An interesting way to think about a gazetteer is to consider it as the space where debate about a place is managed but not decided.
The simplest and friendliest expression of this idea is to consider the many different ways that people spell the name for the same physical location. Sometimes two people who agree on how to spell a name can find themselves at odds when one of them spells it incorrectly. Consider how finicky geocoders can still be about the manner in which a query is formatted and the hilarity that often ensues when a query is entered incorrectly. Now take this dynamic and multiply it by all the languages in the world.
Sometimes the easiest way to describe the purpose of a gazetteer is to say that it exists to make the “spelling mistake problem” go away. If every location has a simple (often numeric but more importantly stable) identifier then you and I can refer to the same place, in any number of different contexts, using that identifier without having to spend a lot of time accounting for linguistic differences or subtleties.
For example I might say “Montreal” (in English) while you might say “몬트리올” (in Korean) while someone else might say “Montréal” (in French) or “MTL” (in Conversational Shortcut) and so on. The gazetteer is meant to be a happy, welcoming and stable space where all those representations of the same place – or if you’re feeling frisky, the same consensual hallucination – can co-exist.
A more complicated expression of the idea that a gazetteer exists to manage debate is to remember that “place” is a hard problem because it is often a contested space at social, political and often very emotional levels. This is not a new problem. People have argued and sometimes fought over the meaning and the expression of place for as long as anyone can remember.
Even with the luxury of complete sentences and full paragraphs and entire books on the subject different writers and scholars still after all these years can’t or don’t or won’t agree on the meaning of a given place. It would be … unhelpful, at best, to believe that any list of key-value pairs, no matter how comprehensive, attempting to describe the nuance of a place will do any better at resolving long-standing disputes about the fundamental meaning and interpretation about that place.
First principles
The gazetteer starts from a series of first principles:
Mapzen has an opinion
It is important that Mapzen have an opinion not about any one place but rather about the nature of place itself. It is important for us to know and understand the boundaries of our project in order to know what the project is for and, critically, what the project is not.
Leave as many decisions as possible to the “edges”
The world is a complicated place and we would like the gazetteer to be a project that can support, or act as a scaffolding for, the sometimes contradictory opinions that people have about it. We aim to leave as much meaning or inference, as we can, about a place to individual users and applications. How this will manifest itself in concrete terms remains to be seen but this is a goal we have set for ourselves.
Portability
The canonical source for a place is a text file, specifically GeoJSON with a unique 64-bit numeric ID. This is because all computers speak “text files” and “numbers”. Text files can be inspected or updated in any old text editor. Text files can be printed. Numbers are fast and cheap for databases to index.
We use text files because our primary concern for the data is: Ease of use, robustness and portability over time. On measure, the benefits of plain old text files outweigh both the costs and in many cases the benefits of other formats.
Google’s Protocol Buffers for example are awesome but require that you install a whole lot of Google on your computer in order to use them. ESRI’s Shapefiles are equally awesome and their ubiquity and longevity is a testament to their utility but they too require bespoke applications for even the most trivial of updates.
That does not mean that plain text or static files are necessarily the optimal choice for delivery or distribution. We will account for that on a case-by-case basis. If we need to pre-process all the data into a smaller and nimbler format for a specific use-case then we will, but you will always be able to access the data as simple text files.
GeoJSON
We use GeoJSON as the primary exchange format for the gazetteer for two interconnected and complementary reasons:
It is structured data with the least amount of markup today. If someone creates another markup language with even less scaffolding we might use that instead but for now GeoJSON is a good happy medium.
There are lots of tools for working with GeoJSON and, importantly, for converting it into all the other formats that different people use.
Tell me more (the hard bits)

If you are immediately curious about the simple bits, where “simple” means names, geometries and minimal viable properties (and which are simple relative only to what follows) then you should jump ahead.
Concordances
Concordances are a good place to start since we’ve already mentioned other gazetteers. Put simply: We want to hold hands with as many other gazetteers – past present and future – as possible.
There is more than enough room for multiple gazetteers in the world and the point of a concordance is only to be able to say, for example, that “our Boston” is the same as “their Boston”. The details of either one of those records may be entirely different because of an individual organization’s focus or perspective. Multiple outlooks on the same subject are a good thing. Concordances allow everyone to work on the things that are important to them while still being aware and acknowledging the work that others are doing and provide a mechanism for all that work to hold hands.
Every WOF record contains a property called wof:concordances which is a dictionary of simple key/value pointers to the identifiers of the same in other databases. For example:
"wof:id": 101736545,
"wof:concordances": {
"fct:id": "03c06bce-8f76-11e1-848f-cfd5bf3ef515",
"gn:id": "6077243",
"gp:id": "3534"
}
As of this writing we have concordances for things from GeoNames (159, 359 of them), GeoPlanet (135, 399 of them), QuattroShapes (115, 550 of them), Factual (80, 973 of them), a variety of airport codes (ICAO, IATA, FAA and OurAirports), Wikipedia pages (just for airports right now) and even concordances for Mapzen Border countries. Soon, we will have more.
Placetypes
For any hierarchy of place types we have identified three “classes” that any one of those place types can fall into. That doesn’t mean there can’t be others (classes or place types) only that these are the ones we’ve identified as a good place to start.
Common (C)
These are, well, common across any hierarchy for any place in Who’s On First.
This part is important: It means that at some point every single record shares at least one or more common ancestors (for example a country or a continent or occasionally just the Earth). That doesn’t preclude very specific additions to the hierarchy for a given location only that those additions need to fit within a common hierarchy shared across all locations.
Common-optional (CO)
These are meant to be part of a common hierarchy but may not be present because they aren’t relevant or because we don’t have the data. Counties are a good example of this.
Optional (O)
These are the parts of a hierarchy specific, typically, to a country or region. For example, the many nested “departments” in France or Germany. The only rule is that an optional (O) place type has to fit somewhere inside the common (C) hierarchy.
So the minimum list of place types for a hierarchy applied globally looks like this:
- continent (C)
- country (C)
- region (C)
- "county" (CO)
- locality (C)
- neighbourhood (C)
A more nuanced version might look like this:
- continent (C)
- empire (CO)
- country (C)
- region (C)
- "county" (CO)
- "metro area" (CO)
- locality (C)
- macrohood (O)
- neighbourhood (C)
- microhood (O)
- campus (CO)
- building (CO)
- address (CO)
- venue (C)
Venues! Buildings!! Microhoods!!! Empires!!!!
So many new things but throughout you can still see a common skeleton. There is an entire Github repository devoted to the topic of placetypes including a discussion (and a canonical reference) about each of the place types described above.
Hierarchies
Hierarchies in Who’s On First are represented as a list of dictionaries, where each item is a dictionary containing a full hierarchy. Like this:
"wof:hierarchy": [
{
"country_id": "85633147",
"region_id": "85683255",
"county_id": "102072387",
"locality_id": "101750223",
"neighbourhood_id": "85794581"
}
]
This is because a location in Who’s On First can have multiple divergent hierarchies. Consider place types like metropolitan areas (the “Bay Area” in and around San Francisco, “New York” inclusive of all five boroughs and even some parts of New Jersey and so on) which often contain multiple children of the same place type. Consider disputed territories. There is a whole separate document about the rationale for this decision and how we arrived at it but the short excerpted version is this:
Reasons why this suggestion is good:Reasons why this suggestion is, or might be, bad:
- It is explicit
- It is easy to compare multiple hierarchies
- It doesn’t require the user do a lot of mental arithmetic to construct the complete hierarchy or to support whatever “efficiencies” we dream up in the moment
- It is easier to change going forward (say before an “official” launch) than the alternatives
- If we support metropolitan areas, then many places (localities, neighbourhood, venues) may have multiple hierarchies where the only difference will (likely) be the county, leaving all the remaining ancestors in common
- File size, disk space and bandwidth - this is the corollary of the first point and akin to whitespace or coordinates with > 6 decimal points in GeoJSON files which can become burdensome quickly
Disputed areas
Although it is true that all neighbourhoods and many localities are “disputed” in a friendly-banter kind of way some places are genuinely more disputed than others because they involve two or more countries (and sometimes so-called non-state actors), a real threat of violence and consequences that in no way resemble “friendly banter”.
For the time being we have explicitly assigned places we know to be disputed a place type of disputed. As of this writing disputed places are parented, in their hierarchies, by two or more countries. This approach does not reflect the subtleties of the facts on the ground in any, of these disputed places. On the other hand it does allow to “block out” areas that are contested and, as we’ve said above, to leave the decisions about how to reflect the dispute to individual applications.
Parent ids and “custody”
Even though a place can have multiple hierarchies we still assume that in most cases there is a single “authority” in place, on the ground. For example, the Golan Heights is disputed by both Syria and Israel, a fact reflected in the place hierarchy, but is still “parented” by Israel:
"wof:hierarchy": [
{
"continent_id": "102191569",
"country_id": "85632315",
"disputed_id": "85632221"
},
{
"continent_id": "102191569",
"country_id": "85632413",
"disputed_id": "85632221"
}
],
"wof:id": "85632221",
"wof:name": "Golan Heights",
"wof:parent_id": "85632315",
In a few isolated cases we really don’t have a good answer for who the parent is or if we’re just not sure because it’s early days and are still vetting the data we will assign a value of -1 for the parent record.
Occasionally we will assign a value of -2. This should be interpreted as “:shrug: the world is a complicated place”. For example, the Baykonur Cosmodrome is a little donut hole of Russia surrounded by the nation of Kazakhstan.
Superseded / Superseded by
One of the large and difficult philosophical questions that working with geography raises is this: How do you decide when something has simply been updated versus when has something fundamentally changed?
This is not a “geo” question per se, only that “geo” has a habit of poking it in the eye. For example Poland, France and Germany spent the better part of a hundred years claiming and reclaiming (and then sometimes reclaiming again) the same territory. Those borders, and the periods during which they existed, are important contextual information for lots of applications beyond just maps. Consider works of art created in those parts of Poland that were German at the time of their creation. How do you create stable identifiers for a location that has changed, in concrete and meaningful ways, over time?
A little closer to home, in New York City, everyone’s favourite that-is-so-not-a-neighbourhood is called: “BoCoCa”. BoCoCa is short for Boerum Hill, Cobble Hill and Carroll Gardens, three adjacent neighbourhoods south of downtown Brooklyn. BoCoCa is neither a name that anyone seems to like, nor is it a place type that most people recognize as a neighbourhood. On the other hand it is a neighbourhood (and an identifier) that has made its way into lots of other maps and datasets. Whatever we may think about it BoCoCa has “existed”.
So in Who’s On First we’ve changed its place type and made BoCoCa a “macrohood” that parents the three neighbourhoods from which its name is derived.
A location’s place type is a pretty fundamental property and it’s easy to imagine that a third-party application might use and store that metadata for important application-specific purposes. Which is to say: We don’t need to have an opinion about what or why an application is doing something with the metadata associated with a location and if we start by saying that WOF ID 85892915 is a neighbourhood (which it was when we imported the data from Quattroshapes) we probably shouldn’t just change it on a whim.
We also don’t think BoCoCa is a neighbourhood, though. We absolutely have an opinion about that. At one time BoCoCa might have been a neighbourhood but in our world it no longer is. The way that we reconcile problems like this is by creating a new record with a new place type (BoCoCa the macrohood) and by updating each record to indicate that one supersedes the other.
For example, the record for BoCoCa the neighbourhood looks like this:
"wof:superseded_by": [102147495],
"wof:supersedes": [],
While the record for BoCoCa the macrohood looks like this:
"wof:superseded_by": [],
"wof:supersedes": [85892915]
It is left up to individual applications to decide how or whether to treat records that have been superseded differently. A search engine, for instance, may choose to weight a superseded place differently or exclude it altogether.
Breaches
Every record has a wof:breaches list attached to its properties. Depending on when you read this blog post, most or all of those lists may still be empty. A “breach” occurs when the geometry of a given location is intersected by the geometry of another location of the same place type.
The purpose of these lists is to signal to users of the Who’s On First data that there is either an error in the data (most country records shouldn’t breach any of their neighbours) or that there is a legitimate difference of opinion about the boundaries of a place (neighbourhoods, for example).
Like many signals its precise meaning and significance and how it should be handled is left up to individual applications.
Tell me more (the simple bits)

Remember, what follows is the “simple” stuff…
Names
All place names were originally derived from the Quattroshapes and Natural Earth datasets. Overall though the GeoPlanet (GP) dataset is better for names in multiple languages, and for colloquial place names. GP defines two properties for a name:
- An ISO 639-3 language code
- A name “type”, which is a well-known list of descriptors as defined by the nice GP people:
The Name_Type field is a single letter code that describes the alias as follows:
- P is a preferred English name
- Q is a preferred name (in other languages)
- V is a well-known (but unofficial) variant for the place (e.g. “New York City” for New York)
- S is either a synonym or a colloquial name for the place (e.g. “Big Apple” for New York), or a version of the name which is stripped of accent characters.
- A is an abbreviation or code for the place (e.g. “NYC” for New York)
GP also distinguishes between a name and an alias so in their world you end
up with something like:
Name: Montréal Language: FRE Alias (ENG_P): Montreal Alias (KOR_Q): 몬트리올
GP does not however account for the fact that some countries have multiple languages. With all that in mind, we decided that:
- We should support multiple languages for a place and label placement
- We should just use
pfor a preferred name, regardless of language - We should use a
namenamespace for names because it is explicit
For example:
{
"wof:lang": ["eng", "fre"],
"name:eng_p": "Montreal",
"name:eng_a": "YMQ",
"name:fre_p": "Montréal",
"name:kor_p": "몬트리올",
}
Geometries
The “consensus” geometry
Every place will have a single “consensus” geometry associated with it. The definition of “consensus” remains to be determined. Also, the use of the word “consensus” is understood to be problematic. It will be deprecated and replaced with a more accurate term.
All the “other” geometries
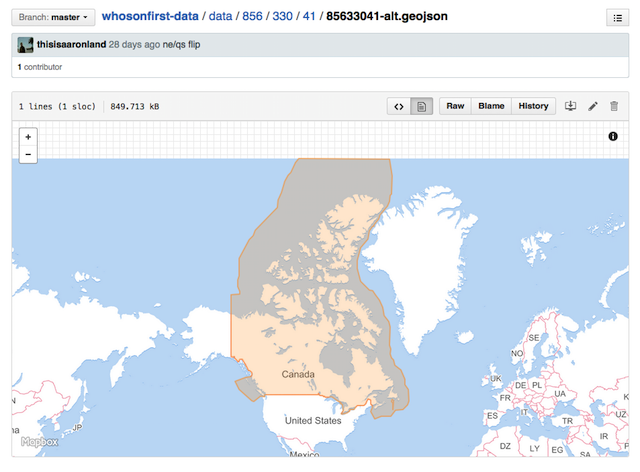
Every place will also have an “alternate” file containing multiple named geometries. These might include contested geographies or simplified geometries or geometries that have been optimized for specific use-cases, like geocoding.
The point is this: ALL THE GEOMETRIES.
The source for the consensus (sic) geometry and all the alternate geometries are included in every record. For example:
{
"src:geom": "zetashapes",
"src:geom_alt": ["quattroshapes", "naturalearth"]
}
Centroids
Any given record can have multiple centroids. It is worth pointing out that “multiple centroids” can be read as a bit of an oxymoron. We use the term “centroid” to denote a specific area of focus for a geometry. Different centroids are denoted by prefixes, indicating their use. For example:
geom:latitudeandgeom:longitude– which are the actual center of the consensus polygon and calculated using the magic of mathematics.lbl:latitudeandlbl:longitude– which are used to indicate the optimal location for label placement. For example, the polygon for San Francisco includes the Farallon Islands which means that the “center” of that polygon is actually in the Pacific Ocean and not an optimal place to label the city.nav:latitudeandnav:longitude– which are used to indicate where, specifically, a routing engine should direct you. For example, the entrance to the ER at a hospital rather the loading bay for delivery trucks arriving at the same location.
Minimal viable properties
The design model for the Flickr API was: What is the one thing you should always be able to do with any photo-related API response?
For Flickr the answer was the “standard photo response” or: You should always be able to load/build the URL for a photo with a link back to its page on Flickr’s website.
In Mapzen’s case the answer to a similar-minded question might be: You should always be able to view API responses on a map.
For example it should be possible to take anything that comes back from Pelias (or any other API) and simply hand it off to Leaflet as a GeoJSON layer and see something on a map.
With that in mind a “minimal viable properties” dictionary might look like this:
{
"wof:id": 85922583,
"wof:name": "San Francisco",
"wof:fullname": "San Francisco, California US",
"wof:placetype": "locality",
"wof:parent_id": 85688637,
"wof:quality": 9,
"wof:score": 100
}
A couple things to note about this example:
When we say “properties” we’re talking about the metadata associated with that place rather than its geometry.
The
wof:scoreproperty and its semantics should be considered a place-holder for some equivalent search ranking to be determined by the Pelias team. Likewise, thewof:qualityproperty and its semantics should also be considered a place-holder for some equivalent quality/confidence ranking to be determined by the Data team.
Future magic (making it)
What follows are a list of properties that aren’t currently supported or are still so “early days” that the easiest thing is to consider them unsupported. They are included here because they absolutely should and will be supported, in time.
Ranking(s)
Quality
How good or confident do we feel about the data included in a given record.
Coverage
Where “coverage” is meant to indicate the number of attributes that have been recorded about a place. We might have excellent names and alternate names for a place but little else in the way of metadata (population, elevation, etc.)
Dates
What are the dates that a place was founded or, in some cases, ceased to exist? This becomes especially relevant in a dataset where every record might be superseded or supersede another.
Dates are actually a pretty complex space so we are going to start with the simplest thing and then gradually grow it to account for the realities of life and of history. The Library of Congress’ work around an Extended DateTime Format (EDTF) is a good place to start poking around if you’re curious about this sort of thing.
But wait… where is this data you speak of?
First – and this is Very Very Very Important – please understand that Who’s On First is a work in progress and that means a few things:
Some (maybe even a lot) of the data will be wrong.
Some things are missing. Some things are missing in a known unknown kind of way in which case they’ll be addressed shortly. Some things may still be missing in an unknown unknown kind of way in which case they’ll be addressed as the errors become apparent.
Some (probably most) of the data will change in some way, if only to account for #1.
We have not formalized or finalized the tools for updating all the ancestors or dependencies of a record when that record is updated. This means that in the short-term it is possible there will be inconsistencies between a record and its relations. We’ll get there.
The purpose of releasing the data now is not to sound the trumpets and herald a new dawn of perfect data but rather to give substance to everything we’ve been talking about and to have a meaningful dataset with which to prove or disprove our assumptions and to work through the practicalities of working with that data.
If you don’t have the time or the temperament (personally or institutionally) to deal with a little bit of on-going bad craziness as we work through the issues then digging in to the data now is probably premature. We intend to continue working in public and discussing the project openly so keep an eye on the blog and we’ll let you know as things improve.
As of this writing the raw Who’s On First GeoJSON data files exist in two places: A public AWS S3 endpoint and as a GitHub repository with lots of tiny little files. Their URLs respectively are:
- https://s3.amazonaws.com/whosonfirst.mapzen.com/data/
- https://github.com/whosonfirst/whosonfirst-data/
Note: The S3 link above is not meant to be a “browseable” thing so much as an endpoint that people know how to work with S3 can start to do stuff with. If those words sound like gibberish to you then you should not click on the S3 link and just have a look at the GitHub link instead.
There is not currently a publicly available tool for browsing the data. We have an internal “spelunker” that we plan to open-source (along with a number of related libraries for working with Who’s On First data) but that is not going to happen today.
The GitHub repository also contains a number of “meta” files, located in the cleverly-named meta directory. These are mostly CSV files with some minimum amount of data for each record of a given place type. Like everything else the meta files are a work in progress but are meant to provide a minimal ability to introspect the data without the need to load everything into a database.
Did you say… “venues” ?
We did. We aren’t releasing any venue data under the Who’s On First banner, yet, but we are working on it. Venues are very much a part of Who’s On First but where they are not complicated they are simply numerous. Often they are both. So, simple things first. Harder things, like venues, will follow.
A word about Git (and GitHub)
Don’t get too attached to working with or managing Who’s On First data in GitHub (or Git in general). We haven’t quite figured out what the best way of both distributing the Who’s On First data or of accepting corrections and suggestions from the community is yet.
Even though the nice people at GitHub continue to do excellent work at making Git easier for a broader population to use, the reality remains that Git is a significant barrier to participation for many people. Absent a more formal decision about an alternative, GitHub at least allows us to point in the general direction of:
- An open and readily distributed dataset that people can download and work with
- A way for people to contribute corrections (and general nuance) about a place
- A way for us to be able to do everything above while still assuring us a measure of authority around the assertions we make about the data
- Also a way for us to think about how and where we store an audit trail (of sorts) for updates to a place
So again: Don’t get overly attached to the Git parts of the Who’s On First data. It is meant to indicate the idea and not necessarily the details.
What is next?

A lot of work is what’s next.
More specifically what’s next is to start releasing the tools and libraries we’ve written internally for processing and managing Who’s On First data, releasing a version of the internal “spelunker” web application that we use to poke around the data and perform sanity-checking, building prototype services on top of all this data, finishing and in some cases starting documentation for all of the above and fixing all the bugs.
Enjoy!
all images by Aaron Cope


{kind=link}
{kind=link}