Impetus
The third post in our Engineering at Mapzen series describes how we use AWS Opsworks to manage the majority of our EC2 resources and the software we run on them. It provides us with a very flexible environment where we can accomodate the range of applications we deal with, without having to run and manage Chef server.
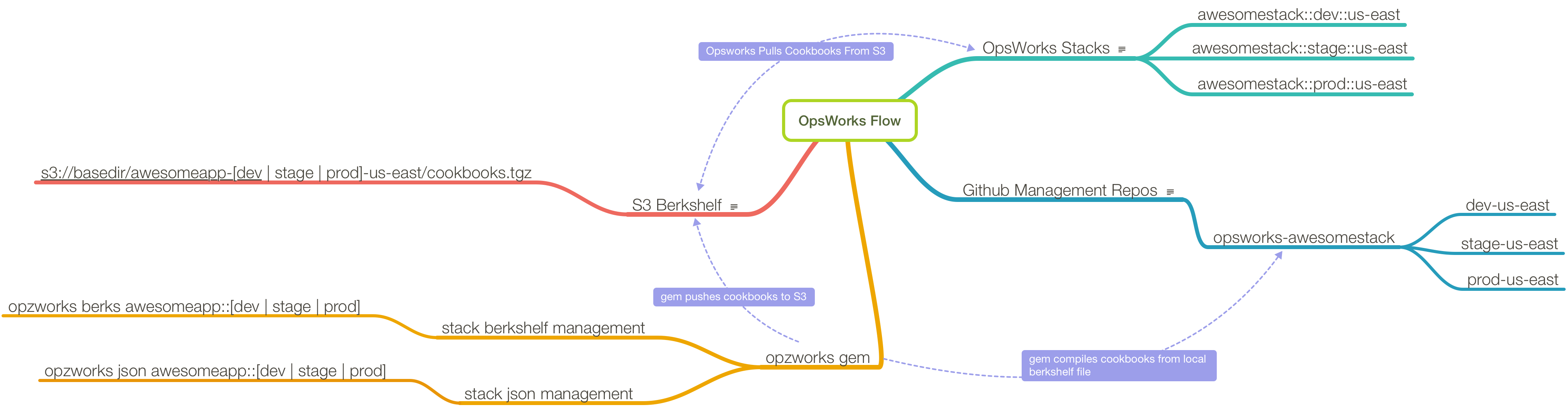
On the flip side of that, we do need to deal with cookbooks for each individual stack we run, which is why we wrote opzworks. Specifically, opzworks allows you to:
- manage a berkshelf for each of your Opsworks stacks as part of a git repository
- manage the json for each of your stacks as part of a git repository
- generate SSH configs from some or all of your stacks
The opzworks Wiki is quite detailed, so please check it out! There’s an A-Z Example of all the setup with a new stack, as well as writeups on configuration and on using the SSH functionality.
Why Opsworks
One great upside of AWS Opsworks is automatic asset tagging. Every EC2 resource launched in an Opsworks stack is tagged with an opsworks:stack key. As you start to grow, this means using AWS cost analysis tools to get a breakdown of where you’re spending money becomes trivial. Simply run a report grouped by stack and you can see which projects are eating into that budget more than perhaps you’d like.
Another thing we like about Opsworks is resource association. For example, RDS instances, ECS clusters and ELBs can all be associated with a stack, making it easy to see at a glance what a particular stack setup is comprised of. Also, don’t discount the Opsworks web interface as unimportant… while all of Opsworks is underpinned with AWS API calls, being able to navigate systems visually to see running instances, associated resources, attached load balancers and monitoring information is all hugely beneficial.
In a company with varying degrees of operational experience, having a platform that allows enormous amounts of flexibility is of great importance. We can manage all our resources in a central location, but still allow people to:
- deploy code by clicking on a button
- write code to automate deployments via API
- deploy a simple rails app with no custom cookbook code using Opsworks built in layers and cookbooks
- write custom cookbook code that manages a large data workflow
- manage access to entire stacks via IAM policies
- manage users (ssh keys)
What need does opzworks fill?
When you start using custom cookbooks with AWS Opsworks, you immediately realize that if you want individual stacks to reference their own store of cookbooks, rather than pull from a common shared repository, you’re going to need a utility to help manage that process. This was the original need that opzworks was written to fill: to simply build a tarball of cookbooks derived from a Berksfile, upload it to S3, and tell the stack instances to refresh their local cache of cookbooks.
The original implementation was config file driven, which meant whenever you added a new stack, you’d need to create a config file that referenced its stackId. The current implementation, however, derives this information for itself, which means you can simply pass it a stack name and it will infer or retrieve via API all the information required to do its job.
Convention & Workflow with opzworks
The use of opzworks requires adherence to a workflow with somewhat rigid naming conventions: for stacks, that means name::env::region. Whether you’re creating Opsworks stacks by hand or via CloudFormation, the requirement to adhere to a standard stack naming convention and cookbook repository structure is a good thing, especially seeing as how a lot of the chef code we write takes advantage of programmatic access to the stack name.
The next convention follows from the first, which is that for each project, there will be one opsworks-project github repo with branches for each environment-region. So if, for example, we have an elasticsearch project with dev and prod envs in both us-east and us-west, you’d want to see…
Opsworks stacks with the following names:
- elasticsearch::prod::us-east
- elasticsearch::prod::us-west
- elasticsearch::dev::us-east
- elasticsearch::dev::us-east
and corresponding branches in an opsworks-elasticsearch github repo for this project:
- prod-us-east
- prod-us-west
- dev-us-east
- dev-us-west
In each branch of the repo you’ll maintain a Berksfile and a stack.json that corresponds to the Opsworks stack.
Now, whenever we want to build a new cookbook bundle for, say, dev::us-east, we can run:
opzworks berks elasticsearch::dev::us-east
This will use berkshelf to create a cookbook bundle and upload it to S3, and at the end of the run trigger update_custom_cookbooks on the stack so that all running instances have the latest cookbook code.
Similarly, stack json would be updated with:
opzworks json elasticsearch::dev::us-east
You’ll be shown a diff of your existing stack json compared with the json you’re you’ve updated in your repository, and asked to confirm the push.
SSH
If you use Opsworks currently and don’t want to re-arrange things in support of this workflow, you still might be interested in opzworks for the SSH config functionality:
ozpworks ssh will generate a config file based off all the instances in your stack suitable for use in ~/.ssh/config. Alternatively, it can operate on individual stacks:
opzworks ssh elasticsearch::dev::us-east
Or on all stacks matching a pattern:
opzworks ssh elasticsearch
There are a few more options, namely the ability to return either private or public IPs, or to just return IPs rather than a formatted config file.
Please check out the wiki for all the details! And if you liked this post, check out the rest of our engineering series.

{kind=link}