
For a while now Pelias, the engine behind Mapzen Search, has supported searching by the default name of Who’s on First records such as Marseille, France. However, not everyone calls Marseille, France by that name: Our Korean-speaking users may only know it as 마르세유, 프랑스 whereas our Bulgarian-speaking users may refer to it only as Марсилия ,Франция. Those used to the Roman alphabet have a hard time finding places like 9丁目, a neighbourhood of Hachiōji, Japan.
To address this, we recently released functionality that supports transliterated names not only in the input query but the output results as well.
Perusing Who’s on First data shows many places with several categories of transliterations for a wide variety of languages. The descriptive categories delineate how places are referred to officially and culturally. For example, New York, NY has a number of names in English:
- preferred: New York
- variant: New York City, NY City
- colloquial: The Big Apple, The Five Boroughs, and Gotham
(“Preferred” and “variant” names are the official monikers for places, whereas “colloquial” names are nicknames that have evolved culturally through various means. And for lack of a better term, “administrative hierarchy” will be used to describe the polygons within which an address exists, such as neighbourhood, locality, region, and country.)
The biggest hurdle in supporting non-default names is storage: there are ~500,000,000 address, street, and venue documents stored in Elasticsearch for Pelias and each has to know the administrative hierarchy it belongs to. Storing the textual names for each language would be both excessive and wildly redundant. There are over 300 transliterated preferred, variant, and colloquial names for France alone in Who’s on First, in a wide variety of languages. Adding language codes and transliterations to each would significantly add to the index size – if this were done, every address in France would have the name France with all France’s variants stored. Certainly Elasticsearch has mechanisms to tidy this up a bit internally, but this approach is still wildly duplicative. Additionally, querying Elasticsearch by text is cumbersome but filtering by IDs is far easier and faster.
To account for this, we added an internal service called Placeholder that provides two key functions to Pelias:
- parsing administrative area parts of queries, such as “Luxembourg” and “Lancaster, PA”
- looking up language transliterations
Pelias still relies upon libpostal as the first parser but since it only returns a single analysis result, there’s a chance that it could misinterpret the administrative area parts of the input. That is, “Ontario, CA” can legitimately be interpreted as both Ontario, Canada and Ontario, California.
Placeholder specializes in geodisambiguation, giving the API the ability to search for an address in various applicable contexts rather than just one. Continuing with the previous example, Placeholder is used to disambiguate all the things that “Ontario, CA” could be so for inputs like 309 E Sunkist St Ontario, CA and 35 Big Tub Rd Ontario, CA, Pelias can unambiguously find the correct addresses in Ontario, California and Ontario, Canada, respectively, despite libpostal identifying “Ontario, CA” as a city/state in both cases:
> 309 E Sunkist St Ontario, CA
Result:
{
"house_number": "309",
"road": "e sunkist st",
"city": "ontario",
"state": "ca"
}
> 35 Big Tub Rd Ontario, CA
Result:
{
"house_number": "35",
"road": "big tub rd",
"city": "ontario",
"state": "ca"
}
The advantage of this geodisambiguation approach becomes very evident in the case of 603 Euclid Ave Ontario, CA as this address exists in both Ontario, California and Toronto, Ontario, Canada, allowing Pelias to return both results.
Additionally, because Placeholder already has the data needed to interpret inputs in a variety of languages, it also has the ability to look up those transliterations for output.
Input
You don’t need to specify language in a query — just enter the address in the language of choice. For example, Марсилия ,Франция will find Marseille, France in Bulgarian whereas 마르세유, 프랑스 will find it in Korean. (Note that the results are in the records’ default language. The next section will cover controlling the output language.)
The city and country don’t even have to be the same language. Pelias will handle the combination, such as mixing Korean and Bulgarian for the city and country to produce 마르세유, Франция.
Various languages also work with addresses included in the query, such as 200 Boulevard Baille, مارسيليا, فرنسا in Arabic and 200 Boulevard Baille, マルセイユ, フランス in Japanese.
Recognition of transliterated names currently works on the /search and /search/structured endpoints.
Output
With the release of this functionality, not only does Pelias understand the administrative hierarchy in a variety of languages, the results from a request can be output in a specific language. Doing so can be done by calling the API in one of two ways:
langparameteraccept-languageheader
The lang parameter is checked first and favored over the accept-language header. Pelias currently supports two-character language codes in the list of ISO 639-1 standard. A warning is returned if the requested language is unknown. (Three-character codes are on our to-do list.)
Marseille, France can be returned in Italian (Marsiglia, Francia) and Icelandic (Marseille, Frakkland). Different language inputs and an entirely different output language work, too. For example, Marseille, France in a combination of Chechen and Arabic can be input and then output in Tamil or Haitian.
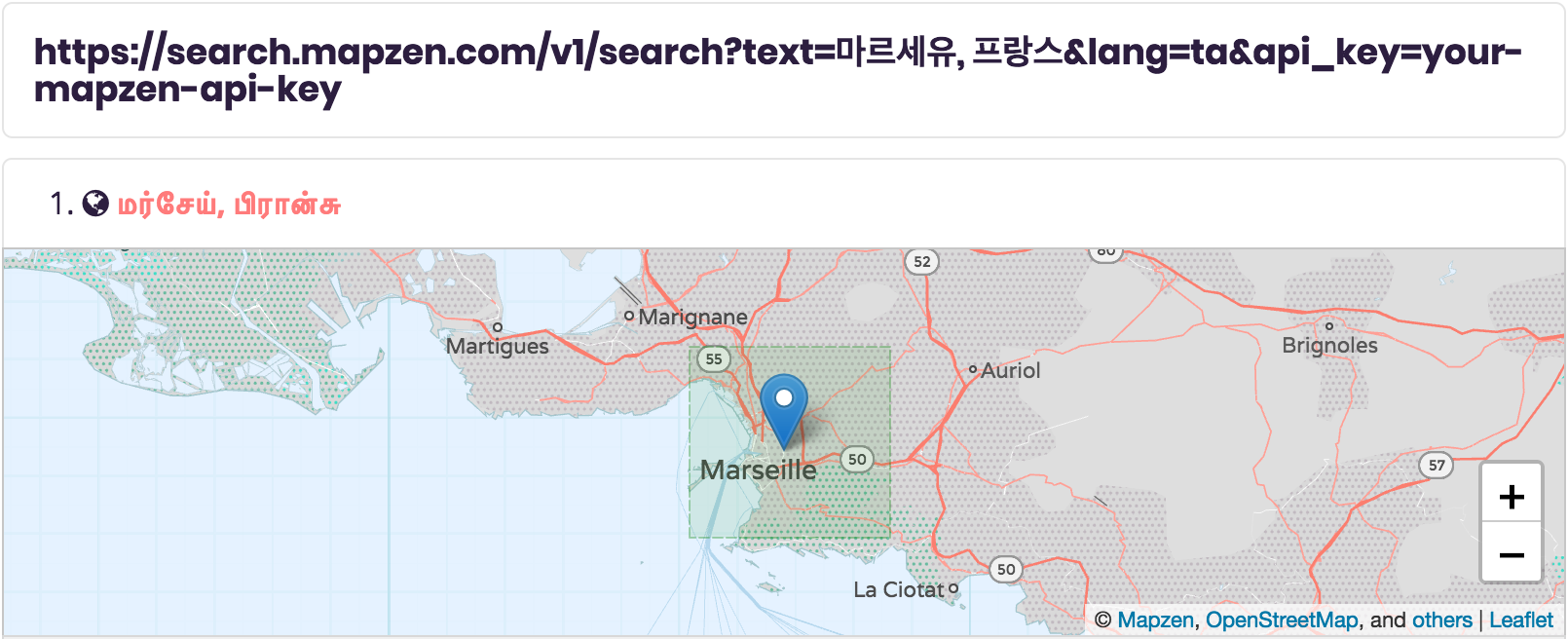
Note that there are not transliterations for every place on earth. In the case where a transliteration is not found for the requested language, Pelias returns the default name for that place, though other parts of the administrative area may be converted. For example, there’s no transliteration of Lancaster to Thai so specifying lang=th for Lancaster, PA would return “Lancaster” as the locality, “รัฐเพนซิลเวเนีย” as the region, and “สหรัฐอเมริกา” as the country. If you’re knowledgeable in a certain language and would like to help out Who’s on First with transliterations, please either submit changes via Boundary Issues or create a GitHub issue.
The Glorious Future
Now that we support transliterations in a variety of languages for neighbourhoods, cities, countries, and everything else in the administrative hierarchy, we’ll start working on doing the same for address and venue names. Stay tuned!
Image credits:

{kind=link}